Optimization, Metrics and Graphs (oh my)
It’s been a while since I wrote about my checkers project. For a few weeks there, I was able to give it a lot of consideration because I was doing the first course in the Deep Learning specialization, Deep Neural Networks. Most of it was a rehash of what was in the basic Machine Learning course, and so I was able to cruise through it in about 2 weeks instead of four. So while that was going on, I was continuing to work on and consider how to build checkers.
For the second of the five courses, rather than do the next one in the series, I picked Convolutional Neural Nets. That’s largely new territory, and on top of that, I’m doubling up with Network Optimization. So for the most part, I’ve had my hands full with those and have only given passing thought to checkers. In the convolutional course, we’re using high and higher level frameworks (Tensorflow and Keras respectively). In building one of the Keras models, without even any explanation, they throw in a “batch normalization” layer. I had no idea what that was, and even if I don’t fully understand something like that in full detail, I do feel the need to at least know what it’s purpose is. So I was googling it and eventually landed here.
Andrej Karpathy again! Twice in two weeks!
Anyway, the link goes right to where he starts talking about batch normalization, but without the context for what he was discussing. So I started at the beginning. In this lecture, he goes through a large percentage of what I’ve already learned, but he has a much bigger emphasis on why certain things work or fail. And the way he does this is by showing plots of the behavior of certain facets of the network that I had never seen before.
In the initial machine learning course I took, we looked really at two main things. First, we spent a lot of time looking at graphs of things like accuracy/error vs. lambda or cost vs. iteration:
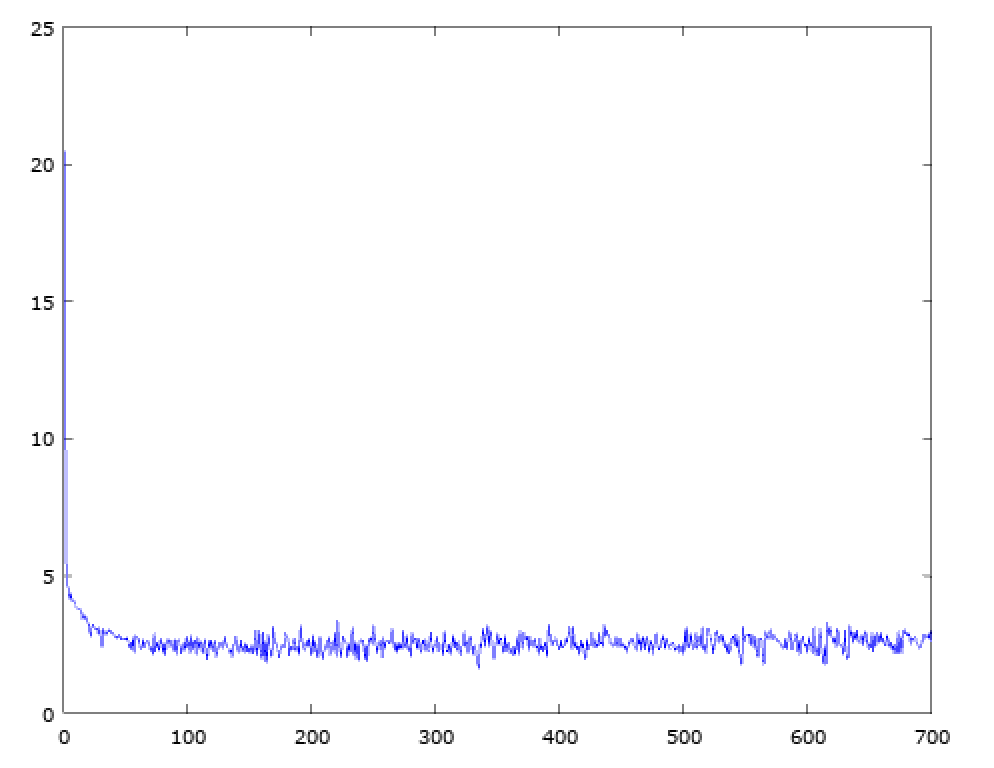
And we also looked at visualizations of the weights of layers of the network:

What he was showing was distribution graphs of the outputs at certain layers of a network to demonstrate what happens in deeper networks if steps aren’t taken to control for diminishing outputs (or sometimes the opposite) on successive layers. This was the first time I realized that especially in deeper networks, they are not inherently stable and can either die or explode if not correctly tuned. Previously, I had thought that what failure would look like is a net that did not learn fast enough, or learn “deeply” enough to be successful, based on the conceptual architecture. What Andrej showed was that at the lowest level, these networks can fail for reasons that have a lot to do with the basic mechanics of the low level algorithms.
So all of this did get me thinking about checkers. I had imagined that once I had decided upon an architecture (such as the as yet unproven ideas I’ve shown already) things would just work and I’d be able to work at the high level architecture to get things optimized and effective. Now I realize that depending upon how I decide to implement this, I need to be ready to get my hands quite dirty looking at the low-level behavior or the system. So for one, if I hand-roll this (more on that later), I need to be able to get meaningful data on the state of the connections of the system to insure that if I’m not getting the results I want, it’s not because the network has died or exploded (or other similar behaviors). I think I may even have seen examples of this in the Keras convnet models we built for our exercise. In building the net shown in the exercise, most of the time, the network was able to learn effectively within a certain reasonable range. But every once in a while, rather than see the binary classifier slowly climb from around 50% accuracy up to the 60s in the first epoch, is would remain pinned at exactly 50% (i.e. random chance) no matter how many epochs got run. Clearly this was a network that had either died or exploded (or something else). I thought about analyzing what was going on, but the reality is that I just didn’t have the time if I also wanted to meet my other life responsibilities (you know, family, job etc.). I figure there will be plenty of opportunity to do that sort of analysis when I’m building something that was already largely prescribed and vetted by the AI experts in my course.
That leads me to another challenge that I’ve thought a good deal about. With the classifiers I’ve been working with, getting those preliminary measures basic viability vs. catastrophic failure has been simple: compare predictions with labels. How the heck am I going to even measure progress with checkers that plays against itself??
I have some ideas on this, but I’ve been knee-deep in coursework for days in a row, and I need a break. I’ll write about this later.