Lost in Translation
![]()
It’s been a while since I posted anything here. In addition to doubling up on my AI course load, I’ve been doing some work on the side for a colleague who’s VP of Development for an AI startup that does assessments. I’ve found some very interesting results in analyzing the semantic impact of machine translation, so I thought I’d document them here.
The Back Story
My friend has been grappling with a tough natural language processing problem, and he came to me to see if I could help out. He’s been using Microsoft’s open-source NLP DSSM, specifically Sent2Vec (S2V) to evaluate the semantic similarity between two sentences. At a high level, the way it works is that with input of an English sentence, S2V generates a 128-dimensional vector representing the semantics of the sentence. A parallel network then does the same for another sentence, generating another 128-dimensional vector. A similarity score is then generated by taking the cosine similarity of the two vectors (effectively a proxy for the angle between the vectors in multidimensional space). Sentences that are semantically identical would get a 1 (co-linear vectors). I’m new to NLP, so this part I’m not sure about, but from what I’ve read, a 0 score means orthogonality, which presumably means sentences that literally have nothing to do with one another. Finally, I’m also inferring that a -1 (180 degrees) would mean exact semantic opposites (whatever that entails).
Challenge
His challenge is that the S2V is only trained in English, and he needs to do these evaluations on Hungarian. It seems his angle of attack for now is training his own model (or something else already out there) on a Hungarian corpus in the hopes of getting a similar level of accuracy to the pre-trained Microsoft DSSM’s English accuracy. He gave me the problem very briefly before going on vacation, so there hasn’t been much opportunity to ask questions. However, after reading more about S2V, I don’t feel optimistic that one could train a latent semantic mapping to be effective on Hungarian with the resources of a startup. As a Microsoft product, my understanding is that S2V was trained on Bing search data, matching queries in one network with labeled web documents via the other parallel network. My assumption is that it has been trained on vast amounts of data—after all, if you’re Microsoft and have access to all of Bing, why not? Furthermore I don’t know what sort of sufficiently large labeled Hungarian corpus my friend could be training his LSM on. It felt like a boiling-the-ocean type problem to do this sort of things with the resources and the time-to-market imperatives of a startup. I could be wrong, but that’s how it felt.
Since my background is as a startup product manager, I’ve placed a huge emphasis on getting something “good enough” to market quickly, and that was the approach I took with this. Specifically, I had what might be a crazy idea: how close could the English S2V get if one were to simply machine-translate text from Hungarian into English and use that text instead? Certainly the results would be worse than using native English, but is it possible that the results would be better than a model trained from scratch by a small startup on Hungarian? It seemed possible.
Thus, step one for me became how to quantitatively evaluate the semantic impact of translation on the results of S2V. Because the only way to do any kind of evaluation would be on English text, I decided that the way to do that evaluation would be to start with some English text and do a round-trip translation from English to Hungarian and then back to English again. I would then use S2V to directly compare the original English sentences to the round-trip sentences. I felt confident that having gone through two translation trips, I could count on the impact of a single trip from Hungarian to English to be less than whatever I would see as the result of the round trip. So the worst case actual scenario from Hungarian to English would be better than whatever I was able to uncover on the round trip.
With very limited time to research alternatives, for translation, I decided to use the Google Cloud Translation API. And for my first round of test text I went with Joseph Conrad’s Heart of Darkness from Project Gutenberg. I figured it’s fairly straightforward American English, and unlike my second round test text, is delivered in a very easy-to-process plain-text format.
How Sent2Vec Works
There were some details of how S2V works that I wasn’t expecting. The first and most obvious, came when I set a baseline by literally comparing every sentence in the text to its untranslated self. I was expecting to get values of 1 returned for everything, but instead, while the values were very nearly 1, they all hovered between 0.9 and 1. Turns out that unlike the face-recognition nets I’ve worked with to date, by default, S2V is not a Siamese network, but rather uses two different networks for what they call the “source” text and the “target” text. This makes sense in the context of how the model was trained for the job it needs to do. If you have to create similarities between, on one side, search terms, which, among other things, will be on the shorter side an possibly more broad than the target, and the various potential target documents—in this case, web pages—it makes sense that you’d want different networks trained on different data sets for each.
Fortunately, for any sentence to sentence comparison, you can choose whether to use the source or target model for either sentence being compared. When using the same model, sure enough, comparing identical sentences returned 1s across the board.
The Results
So, what were the results? Well, in addition to the two models, source and target, both of which I tested as Siamese networks, you can also choose the type of model: DSSM and CDSSM (the C stands for convolutional). So I was testing all 2557 valid sentences in HOD on four different combinations: source and target, and for each of those, DSSM and CDSSM. Here are the results:
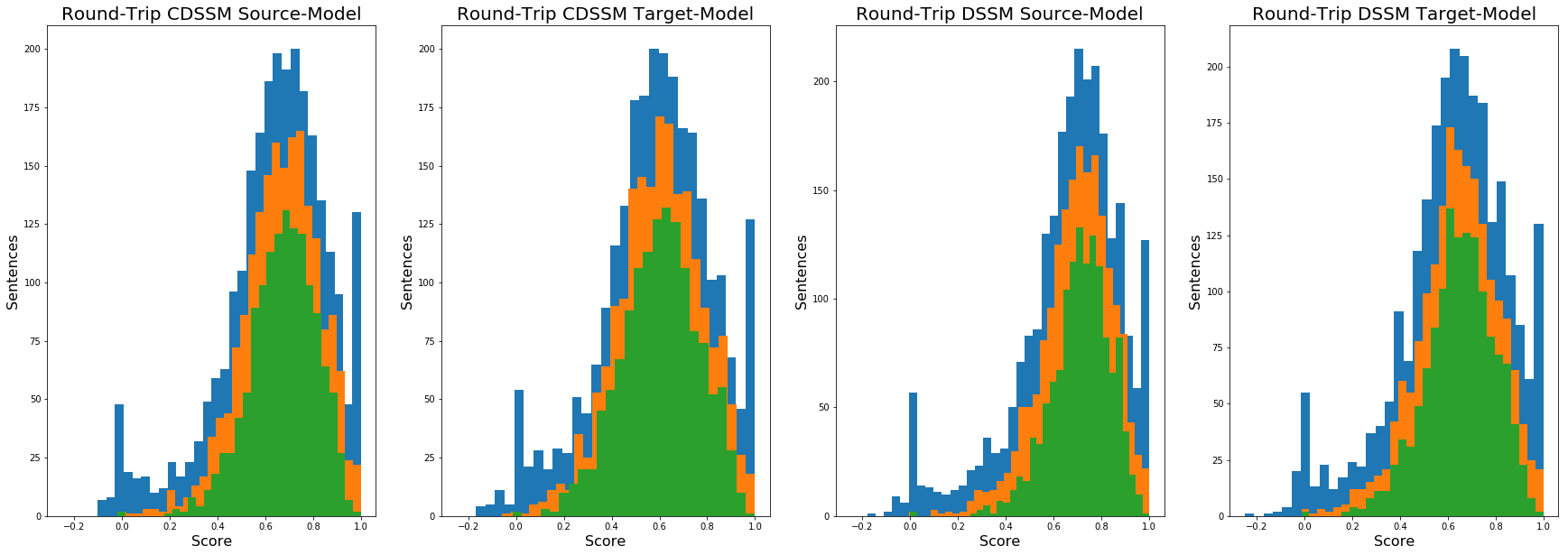
The blue histograms are more or less, the complete set of sentences. I also tested just sentences over 5 words (orange) and over 10 words (green). There’s not a lot to separate any of it, and the best score for the full set was DSSM-Source with a mean of 0.66, bumping up to .71 for just sentences over 10 words. In the full set, there are also spikes from the distribution at 1 and at 0. The 0 scores are basically errors. I didn’t spend a lot of time cleaning the data, and there were things (like ellipses) that the sentence tokenizer I used took as sentences. Getting an exact 0 is the equivalent of an error. The 1 scores are an anomaly too. Since it’s probably impossible to get something semantically identical translating from language to language, I figure there were certain sentences which may have drifted semantically on the way out, and by chance, drifted back to the correct sentence on the way back.
I can’t yet say whether or not these results are worth pursuing for the purposes of the project. Honestly, this is farther off than I was hoping. With a mean of .66, that adds up to a 48 degree mean difference between the vectors. But I did have the following hypothesis: that on the round trip, perhaps the mean of the angles between vectors might be equally accounted for by both the outbound and return trips, and the cosine similarity might be more like .91 (accounting for an angle of 24 degrees). So I decided to send the sentences that had already taken the round trip and send them on another round trip, and compare the original English to the resulting sentences that had been on two round trips.
Here are the results of that (just on the full set of text this time):
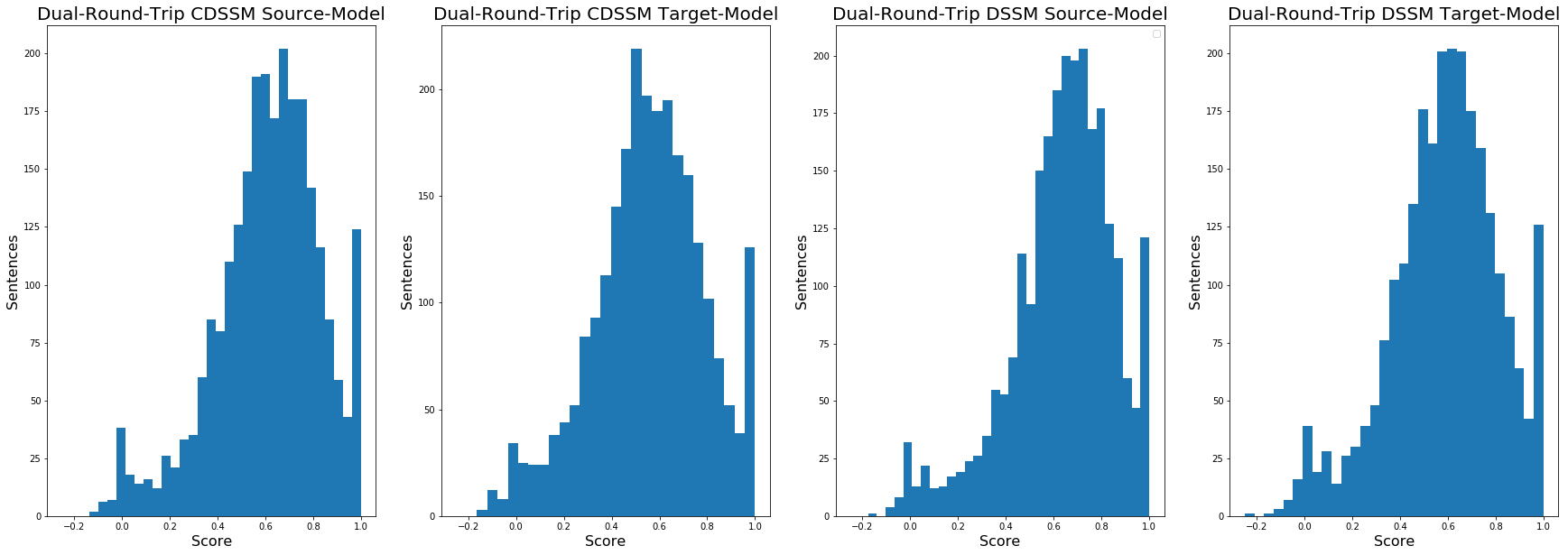
There’s slight degradation, but just looking at the histograms, it would be difficult to even notice that the best 0.66 score from the original round trip had even slipped at all going the full dual round trip (it slipped slightly to .63). The standard deviation didn’t noticeably increase either. So what the heck is going on here? To answer that question, I decided to just compare the sentences after the second round trip to where they were after the first round trip. Here are the results of that:
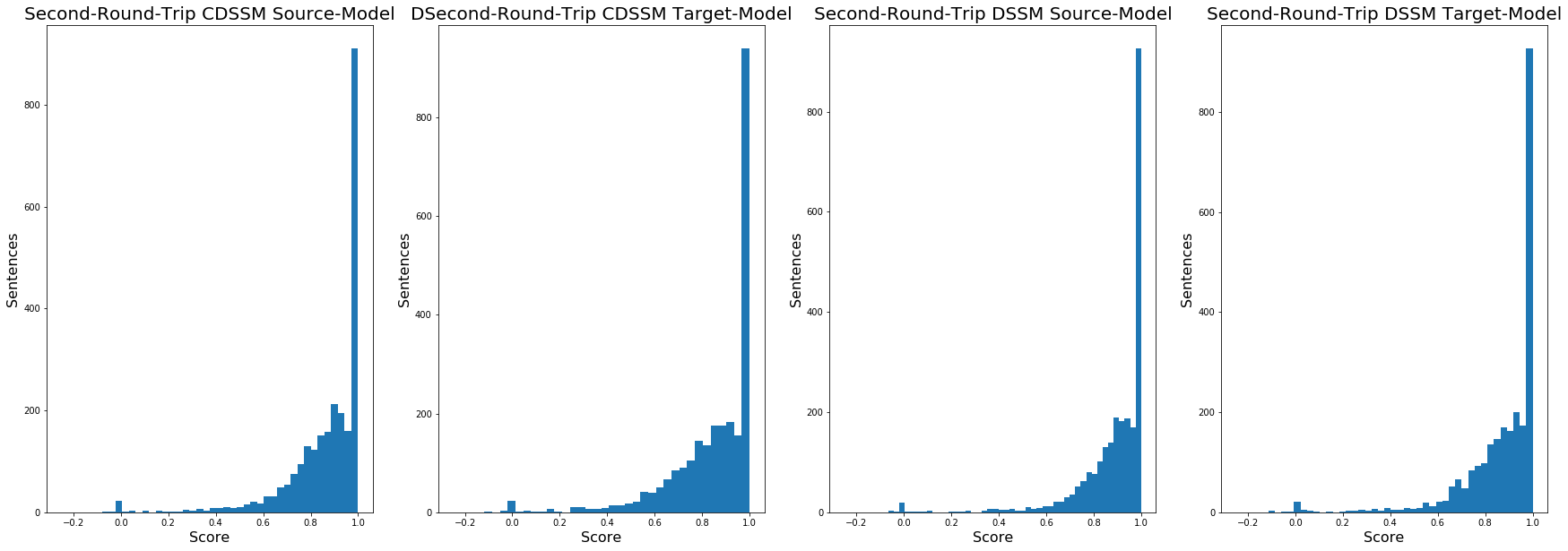
That was not what I was expecting. Fully 1/3 of those sentences survived the second round trip completely intact, identical to the sentences after the first round trip. The best mean score (again on DSSM Source) was 0.88 with a standard deviation of 0.17.
What’s going on here? Why does the round trip text stand up so much better to another round trip than the original text did to the first? As a former English major, I was tempted to think that the translation API had stripped the poetry out of Conrad’s text. After all, despite being written in relatively straightforward English, this is Joseph Conrad, who was who he was for a reason. For instance, here is the sentence at index 100 of the original pre-processed text:
The traffic of the great city went on in the deepening night upon the sleepless river.
There’s poetry there. Especially “sleepless river.” But here’s the round-trip text:
The traffic of the big city continued in the depths of the sleepless river.
“Sleepless river” survives in tact. There is some semantic drift, but nothing dramatic. If I were anthropomorphizing the translation API, I’d say it’s slightly misunderstanding certain things. Here is the dual round-trip sentence:
The traffic of the metropolis continued in the depths of the dreamless river.
For some reason, this time around we lost “sleepless river,” but in general, theres just more drift. And at any rate, anecdotal inspection of a single sentence (or even many sentences) are not likely to yield definitive answers. Which is why I decided to run the same experiments on a different, less “elite” set of text. I used the Blog Authorship Corpus which consists of the collected posts of 19,320 bloggers gathered from blogger.com in August 2004.
After processing, it’s many orders of magnitude larger than Heart of Darkness so I took a random sample of 2,500 sentences from that corpus, and ran it though the first round trip. Here are the results:
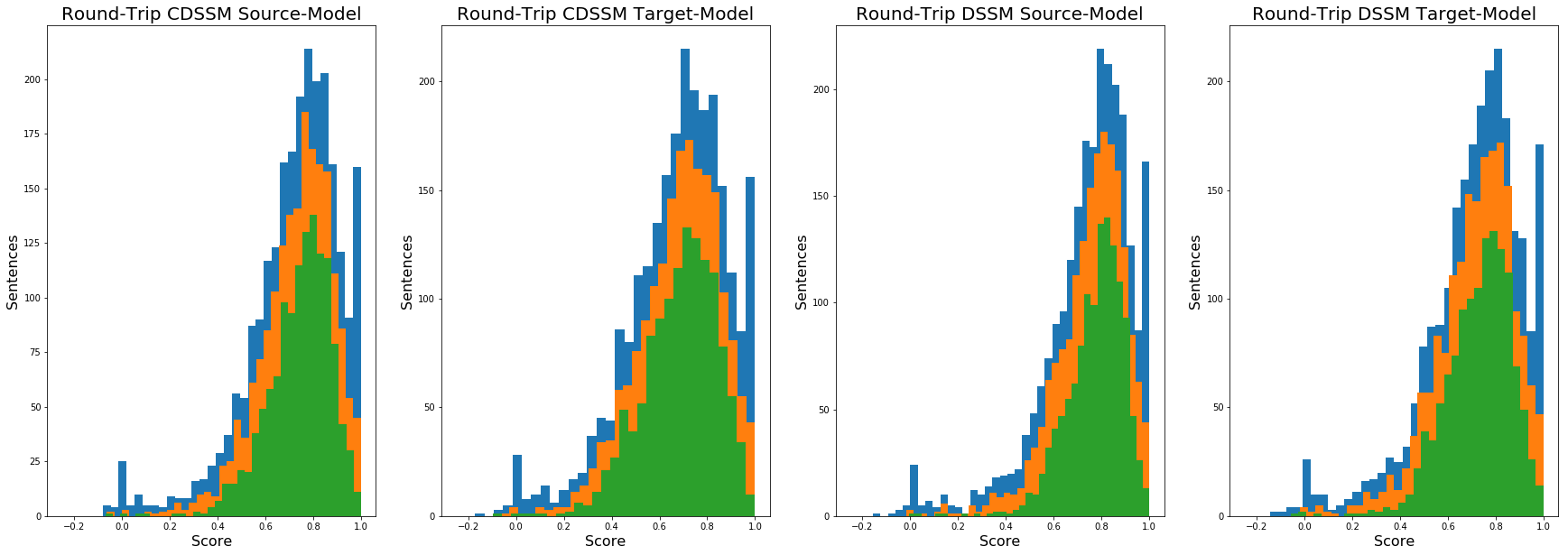
As with HOD, there’s not much difference between the models. And as with HOD the best score for the full set was DSSM-Source, this time with a mean of 0.74, bumping up to .77 for just sentences over 10 words. And the dual round-trip also shows similar results to HOD:
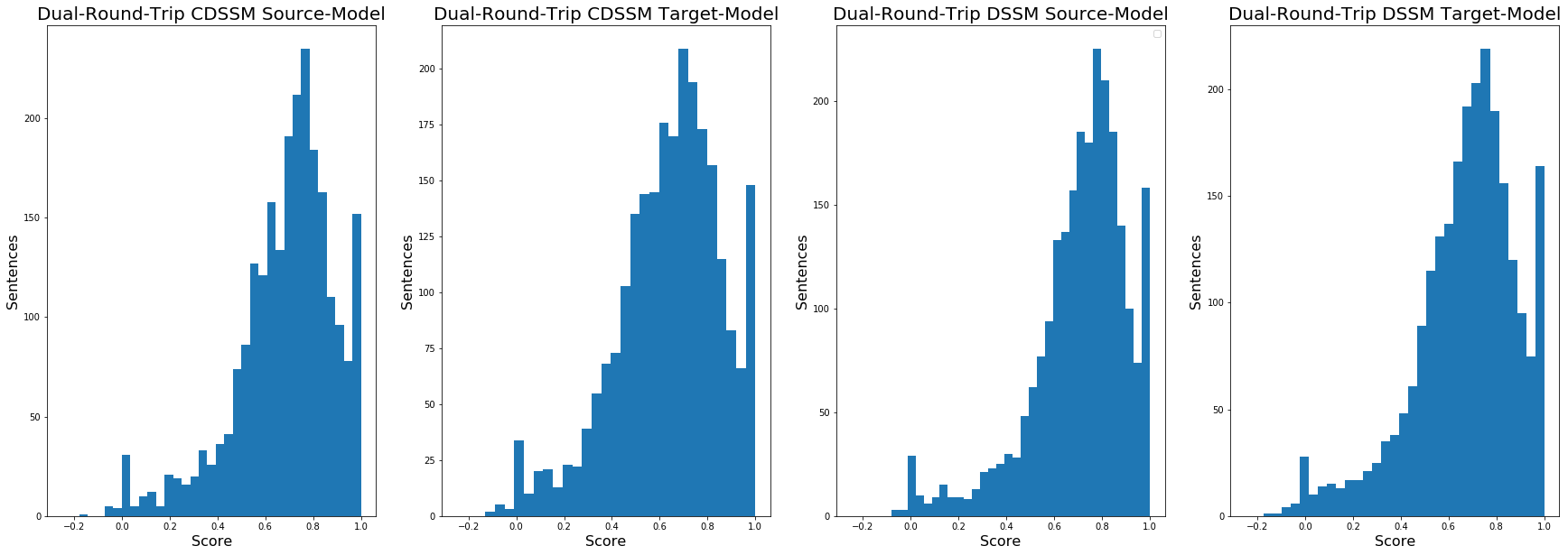
And finally, the results of just the second round-trip:
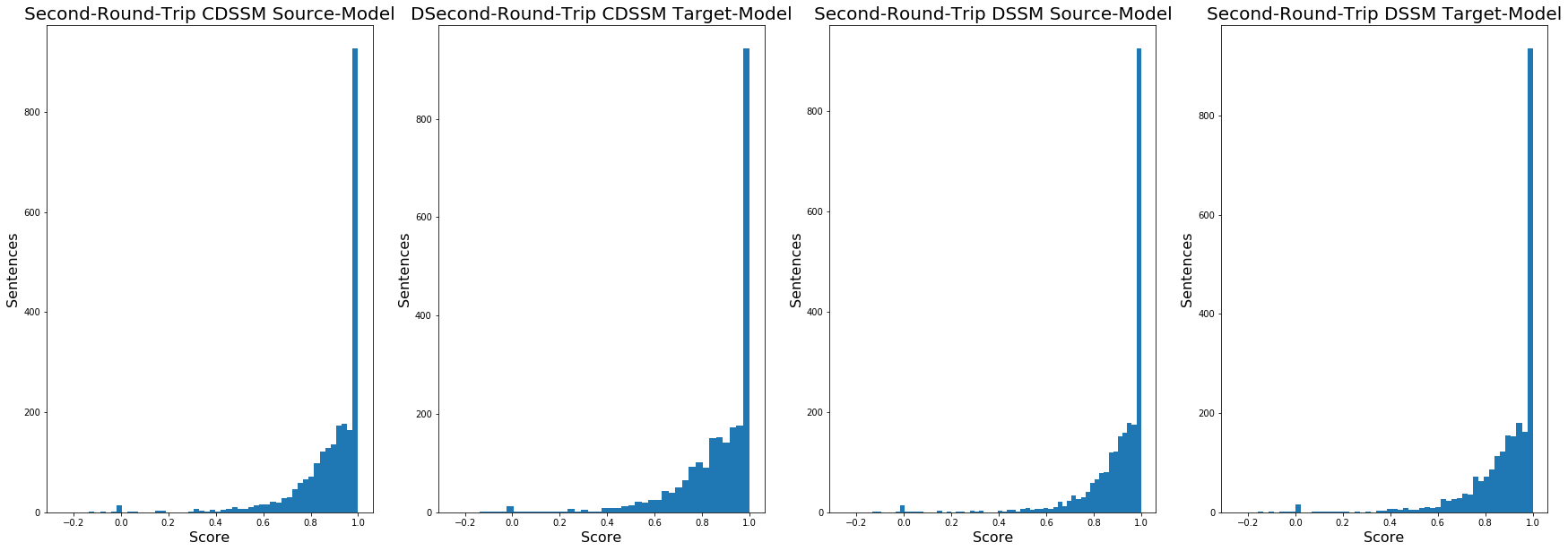
Same scrubbing effect as with HOD.
It struck me that this could be a limitation of the vocabulary incorporated into the translation engine. But that doesn’t seem likely. If I had more time I might study this more. One thing that might be interesting would be to run the text through, say, 20 or 30 round trips and see where it lands.
Sadly, though, I have to keep my energies focused on more practical matters. At this point, that means finishing my second-to-last DeepLearning.ai course, Sequence Models which, incidentally just covered NLP, and making some progress on the checkers project…