Inexplicable Results Explained
Built a quick (slow) framework to track board state and proposed illegal and legal moves for every game, and save out the game history for any game where the illegal move percentage spiked to higher than 98%. The vast majority of those illegal move spikes were as a result of mandatory double (or more) jump scenarios.
Turns out the reason I was getting those inexplicable results (specifically, illegal moves would start to spike really high at around 30,000 games) is that I actually had a bug in my input feature array, and a very important one. With one exception, a sufficiently robust network should be able to infer everything it needs to know about what moves are legal from the current board state. The one exception is when the current move is the second (or later) move of a multiple-mandatory-jump scenario, exactly the scenario where those illegal moves were spiking. In that situation, the my input vector was supposed to explicitly give the network a jump piece number (in one-hot form). Specifically, the piece on the board that was required to jump, without telling it anything beyond that. In the event that there was no mandatory jump, I would feed the network zeros, implying no mandatory jump. In the mandatory jump follow-up scenario network is then supposed to infer from training that only that piece may be moved, and that it must be a jump.
My problem is that thanks to a bug in the code, I was always feeding the network a zeros vector, regardless of whether there was or wasn’t a jump. This meant that the network had no way of knowing that, instead of being able to move any piece to otherwise legal positions (via jump or move), there was only one piece on the board that could be moved. Thus, as the network got more and more trained for legal moves, often it was in a situation where there was only one legal move available, but the probability output for that particular move had been trained to be much lower than random chance, so it might make 1,000 incorrect attempts before coming up with a legal move.
So I fixed the bug, and passed that number. And realizing that even with that vector, it might make sense to be more explicit about the mandatory jump scenario, I also added a jump flag to my input features: a 1 when a mandatory jump was required, and a 0 when it was not. So the input would now have two important features for those situations: is a jump required? And if so, what piece is required to jump.
Here are the results. From before this fix, here are the outputs without the mandatory jump information provided:
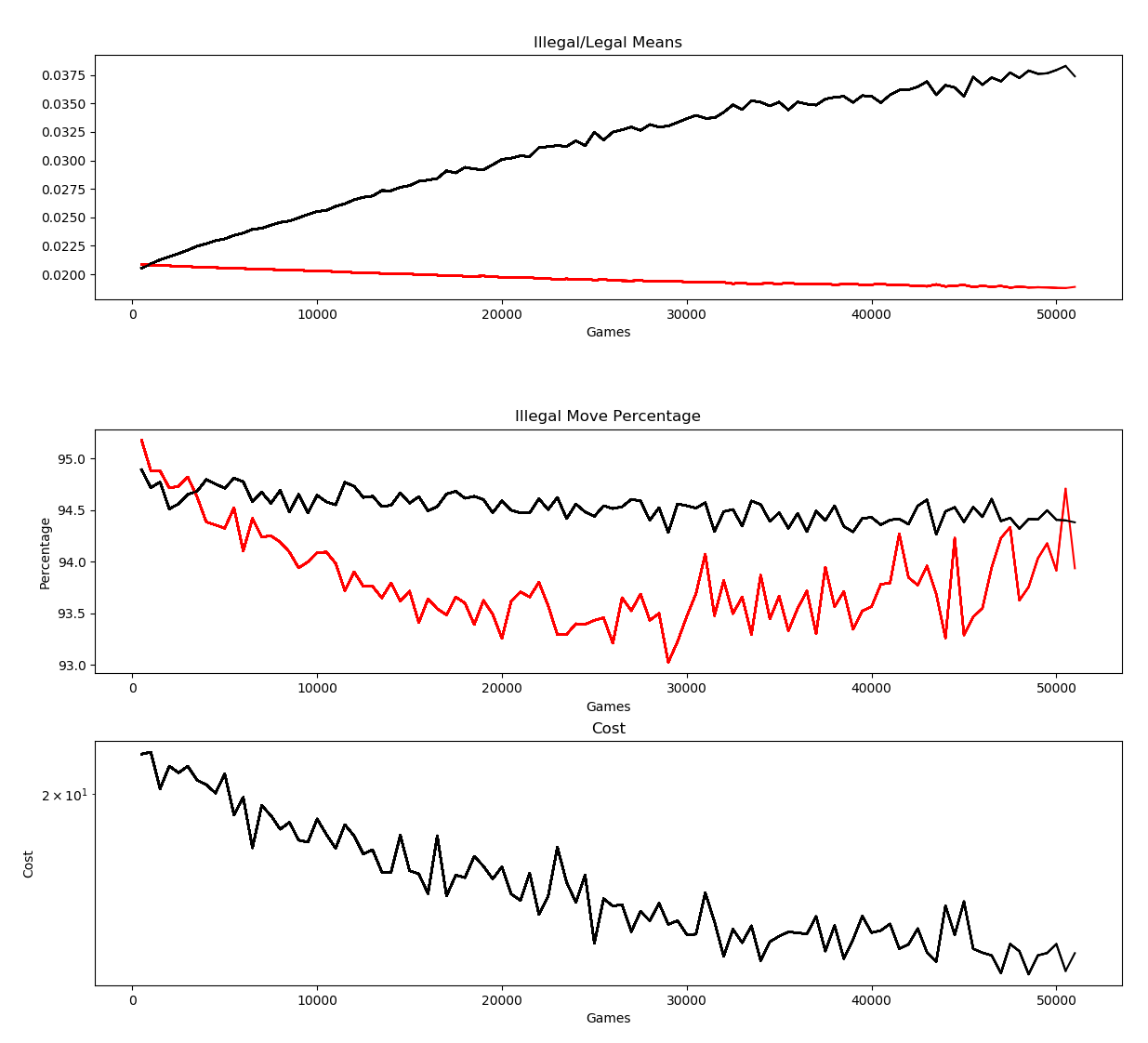
We can see that around 30,000 games, illegal moves start trending upward again, presumably as a result of training not taking into account mandatory jumps. After putting the fix in place, I ran the training all night there’s an improvement but still a problem:
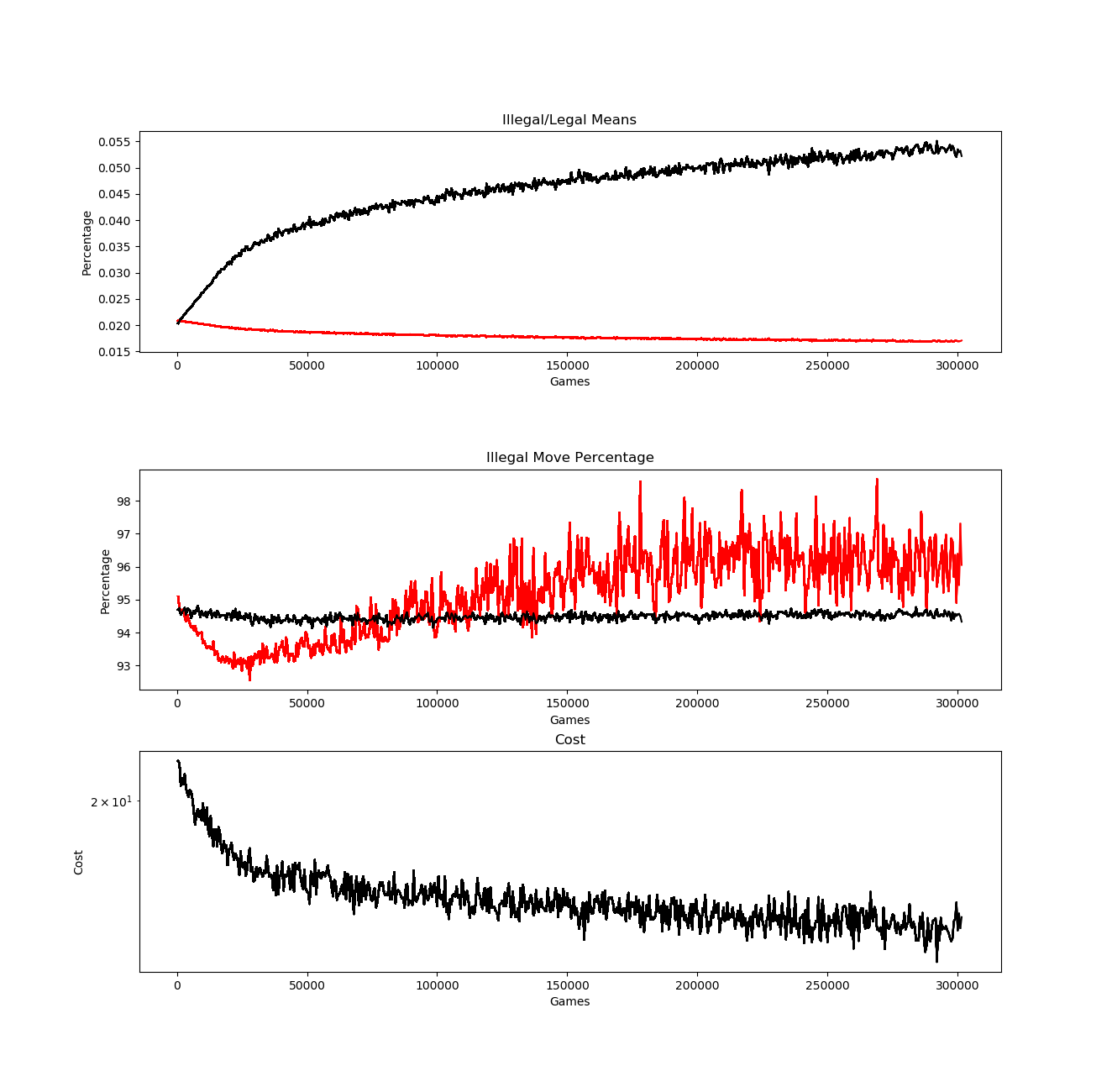
The percentage of illegal moves gets pressed lower, and while it takes a good deal longer, eventually starts trending upwards again, and then illegal moves end up much higher than even random chance, even with the input vector including the jump piece and jump flag.
So I had a realization. I think using the current cost function it’s inevitable that the percentage of illegal moves will never really get close to zero, and will often suffer from worse-than-random-chance results. Here’s why.
Right now, in any situation, such as when there are 6 possible legal moves, the label for each and every legal move is 1 (and 0 for all the illegal moves). In general, that creates very strong reinforcement for those outputs. But in the more rare scenario with just one legal move, that lone legal move is also reinforced with a 1. It’s relatively rare, and there’s no way to pull that single legal move scenario above the probabilities created by all the rest of that signal. I realize this is a very fuzzy way to talk about it, but I think it’s correct. We see that one important metric from above is that the mean for legal moves moves progressively up with training, which, in general is as it should be. The problem, I believe is that they’re getting pulled up too much. It works well in certain scenarios, but those higher numbers basically overwhelm the scenarios when there’s just a single legal move. In some scenarios, that legal move which should have a much higher probability than everything else on the board, often (and I’ve seen this) has a significantly lower probability than even quite a few other illegal moves. That can cause one single move to have 600 or 700 attempts before probabilities land on a legal move.
Ultimately, though, the solution now seems obvious (famous last words). In a one-hot supervised learning situation, a network would tend towards the one-hot value. With enough training, the probability of that output would be very close to 1, with all the others very close to zero for a very low loss value. However, with the way I’ve set it up, while multiple outputs can all simultaneously tend towards 1, it’s never actually theoretically possible for more than one output to achieve that. Optimizing a cost function to achieve that is likely to generate poor results.
Since a softmax nonlinear output always sums to 1, my labels need to do the same. Thus, a scenario with, say, 5 legal moves should have the labels for each legal move be .20 rather than 1. But what this also means is that the scenario where there is only one legal move will have a 1 for the label at that output, which will allow, over time, that to not get drowned out by all the other outputs.
Time to get to work.