True Cost
It’s been a while since I posted anything here, and in fact, a good while since I worked on this project. Shortly after my last post, school started for the boys, and that’s always a bit of a transition. Also, I have been interviewing for a job. I also decided it was time to complete the training to be a Deep Learning and Neural Networks mentor for DeepLearning.ai, so I did that and have also invested a good deal of time doing some actual mentoring.
Running Around in Circles
But now I need to get back to it. The last thing I posted was my change to my labels. My problem with using 1 for legal moves and 0 for illegal moves is that they were not unit normalized. I believe that having the legal (“correct”) moves sum to more than one was what was causing the illegal move percentage, after going down significantly, to trend upwards like so:
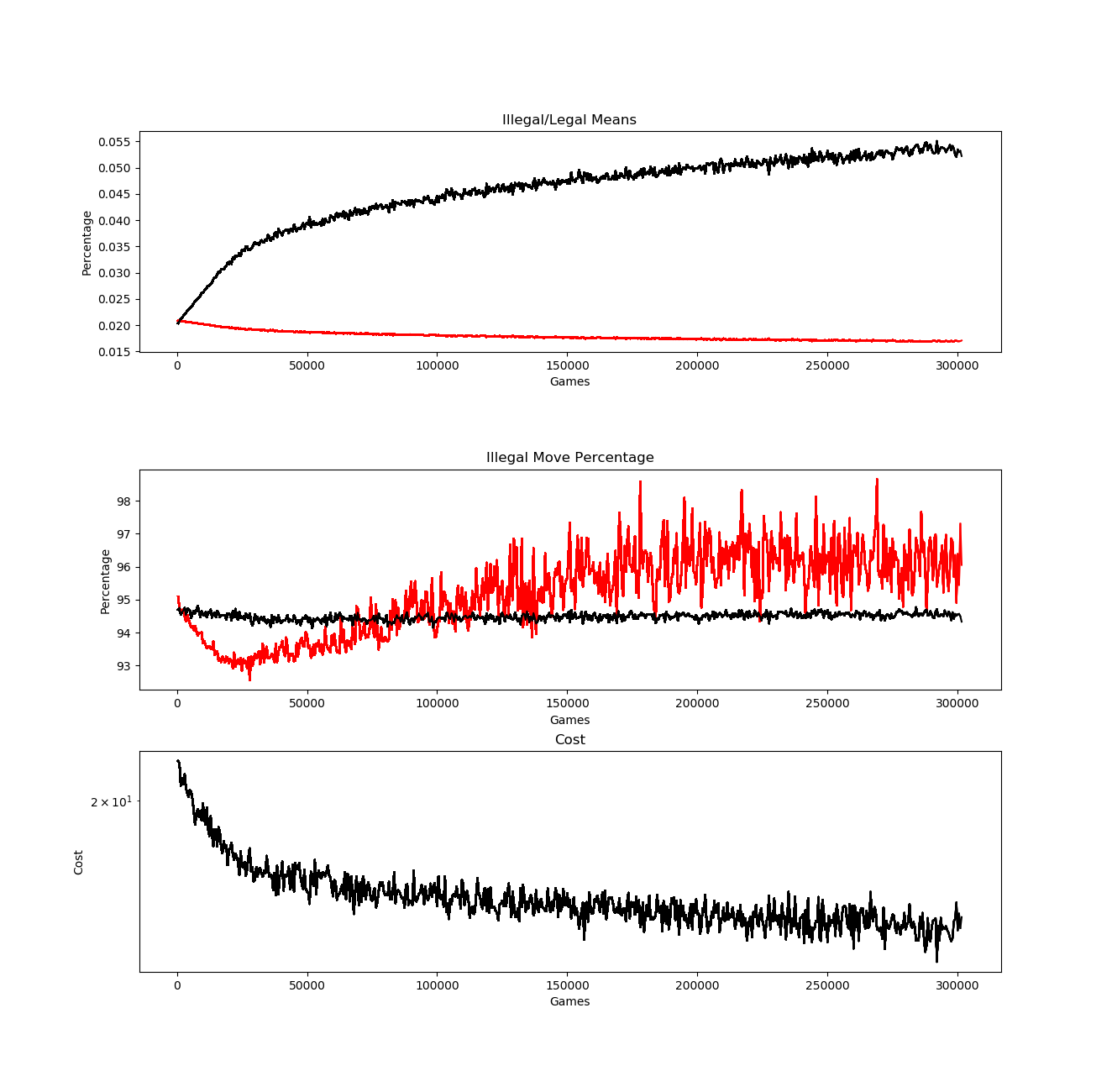
So I unit normalized the set of legal moves (they now sum to 1). Unfortunately, this did not solve the problem. Eventually, it still creeps up above the level of random chance, which means that even with unit normalized labels, the probabilities are not correct.
I’ve looked at what’s going on in these situations, and the reason this is happening is almost always, there is a situation where there is a single legal move available, and yet some illegal move (or usually, some group of illegal moves) has a combined probability that far outstrips the probability for that one legal moves. So a single move correct move might end up requiring in excess of 1,000 illegal moves to get there. This completely blows up the probabilities.
Here’s my hypothesis on why this is happening. Even after the unit normalization of legal moves, the cost of illegal moves is still not being taken fully into account. Random guesses for legal moves has shown to generate, on average, about 17 illegal moves to get to each legal move. So, for instance, let’s take a scenario where it takes 5 illegal moves to get to the one legal move (one side of that bell curve). The way I’m training the system up to now, that becomes a single training example, reinforcing the legal and illegal choices as described. But let’s take another scenario on the other side of that bell curve where it takes 58 illegal moves to get to the legal move. Clearly those probabilities are farther off the mark than the first scenario. And yet this second scenario also just gets a single training example. The cumulative effect of this is that these cases on that side of the bell curve get much less reinforcement than they deserve, and the ones on the other side of the bell curve get far more reinforcement than they deserve. In the long run, this will have the effect of increasing the likelihood of those scenarios relative to the other ones. Even if it doesn’t happen that often, when it does happen, the effects are enough to throw off the cumulative effectiveness of the model as a whole.
The solution I came up with for all of this is to not just create and use a training example for each move ultimately made in the actual game, but instead, to create a training example for each proposed move, every one of which is illegal right up until the final, legal proposal. The intended effect of this would be to reinforce that first scenario six times, once for each proposed illegal move and then one for the ultimate legal move. The model would be reinforcing that second scenario 101 times, taking into account the appropriate cost for those probabilities.
At present, I’ve done this in the most naive, simplistic way possible. Specifically, that six training example scenario simply trains the exact same inputs, probabilities, and labels six times in a row. Likewise, that second example trains the same inputs, probabilities and labels 101 times in a row. Since, as I mentioned, random chance generates about 17 illegal guesses for each correct guess, I now have 18 times the training examples, incurring 18 times the computational cost, with no new actual data. I’ve considered ways to accomplish this with just a single training example for each ultimate move, but it’s actually quite tricky and so first, I’m just going to see how this does. If it works, perhaps I’ll invest the time into working out an efficient algorithm to accomplish this.