Tensorflow, *sigh*
I started a new job running product for an AI startup, and it’s been pretty intense, not leaving much time to do my big TensorFlow conversion. But over the last week, I got back to it, and yesterday I got the forward and backward prop working for the first time. With a few exceptions, I built everything at pretty much the lowest level I possibly could. For instance, rather than use things like tf.layers.dense(), I used matmul operations on raw parameters and inputs. I did feed these outputs to tf.nn.relu() and tf.nn.softmax(). But I ended up writing a custom mean square error cost function. This is largely because the built in tf.losses.mean_squared_error() was not behaving as I would have hoped, and not finding detailed answers to how to get it to work correctly, my short-term fix was just to translate my hand-coded NumPy cost function into tensor flow. After a little debugging, it worked just fine.
First Downside
The first thing I noticed once I got things running correctly was that the model was playing games significantly more slowly than my hand-coded python network. At first I had attributed this to the fact that my test machine uses tensorflow-gpu (on a very powerful GPU). I had come to understand from various sources that copying from CPU to GPU and back was an expensive operation time-wise. I had assumed that this might be slowing things down. So I switched my Anaconda environment to one that used garden variety TensorFlow and tested that. It was just as slow.
What I’m assuming at this point is that the combination of TensorFlow’s overhead and the way I’ve architected the playing and training algorithms is the problem. Specifically, the way it works is that to make a move in a game, the model makes a single forward prop prediction. Then it waits for the other player to move. Then it makes another prediction. My assumption is that the overhead necessary to run forward prop on the TensorFlow network makes just running a single prediction at a time very inefficient.
I’ve come up with a possible solution. Right now I’m typically running a batch of 1,000 games before training. My thought is that I could run those games in parallel. I could construct a matrix of the 1,000 opening board positions and get forward prop predictions for the first move of 1,000 games all at once. Then for the next move, I could feed the board positions for each of the 1,000 games again, and get the predictions for the second move of the game all at once. Etc.
The problem with this is that when I designed the mechanics of how games are played and tracked, it really wasn’t designed with this in mind. To do so would mean some very tedious, error-prone and time-consuming refactoring of the architecture. At first, I was debating whether to do it at all, since as I’ve mentioned several times, this whole challenge of learning to make legal moves is not really what I set out to do in the first place. But the thing is, first, I feel that it will probably be a good exercise to rework things in this way. But more importantly, at the time that I do get to doing my full-on learning-to-play-checkers AI, it will almost certainly be vital to maximize the efficiency of the game-play (which is, after all, where the data is coming from). So I think I’m going to need to do that.
Second Downside
Not that this is a surprise, but the network I built in TensorFlow suffers the exact same catastrophic failure that my hand-coded python network does. This time, I have the graphs of the data that shows this happening through the full set of trainings:
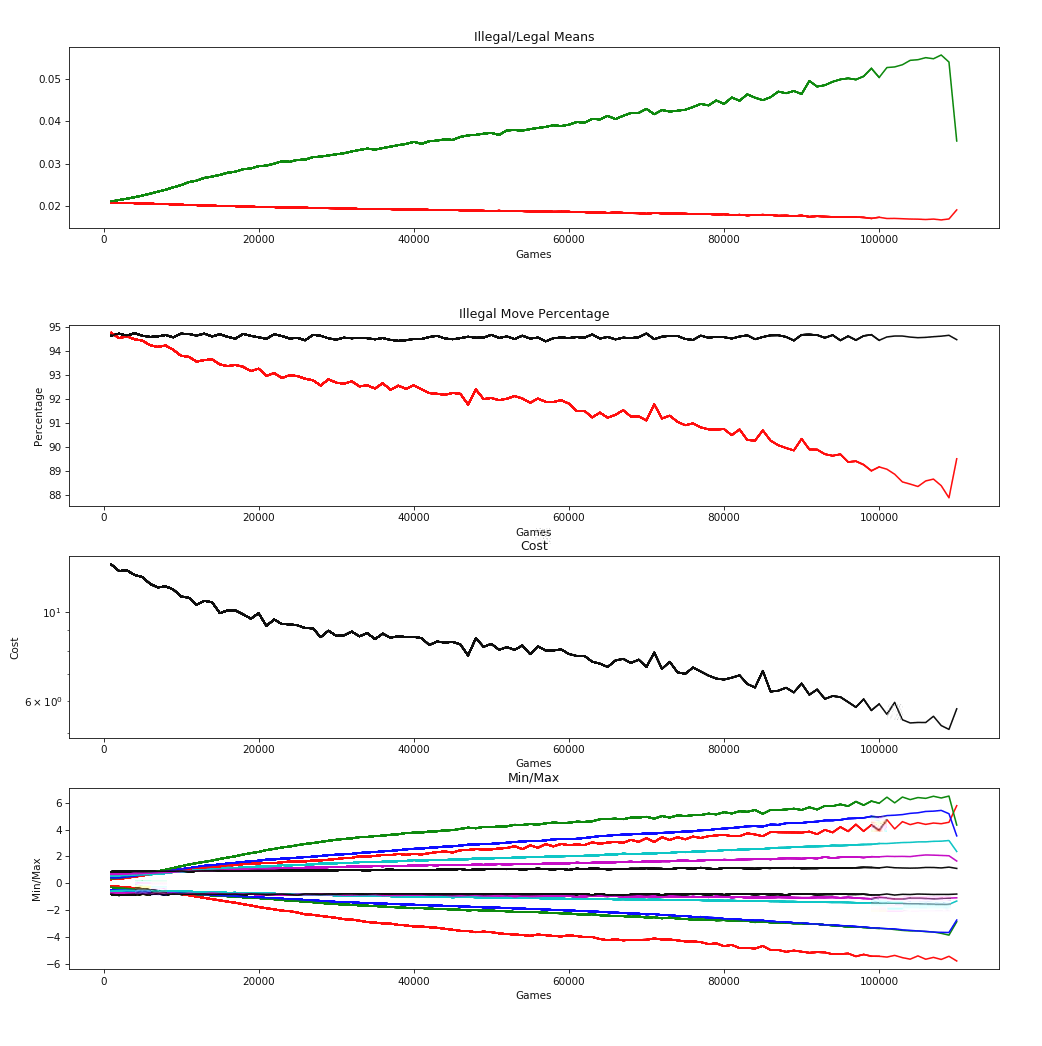
Since I have the saved parameters from after the explosion, I’ve been able to verify that the model, for some reason, is generating a single 1.0 output with all the rest zeros. I truly don’t know if I’m going to spend the time to figure this out. It is, however, killing me that I don’t know why this is happening. I could really get down into the weeds and see the exact mechanics of it, but I don’t think I’m going to do that.
Instead, I think I’ll try two things. First—and most basic—is what I mentioned previously: regularization. That’s just a line or two of code, so it should be easy. I could have done that almost as easily in my hand-coded implementation, but I’m on to this now, so I’m going to do it here. The second thing I’ll try is batch normalization. While it wouldn’t have been absolute rocket science in the hand-coded version, it would have been time consuming to both implement both the straightforward forward prop algorithms as well as the less clear-cut back prop. Doing it in TensorFlow should be fairly easy. The only wrinkle is that I will probably have to convert my hand-coded TF matrix multiplications with discrete parameters into higher level TensorFlow layers.