Andrej Karpathy to the Rescue (of Course)
What a difference a great teacher makes.
Recently, I completed the Coursera Generative AI with Large Language Models course. As I alluded to on LinkedIn, it was a letdown. It didn’t explain the mechanics of how LLMs work. The closest we got was the classic diagram from the now-classic 2017 Attention Is All You Need paper introducing the transformer architecture and some high-level explanations.
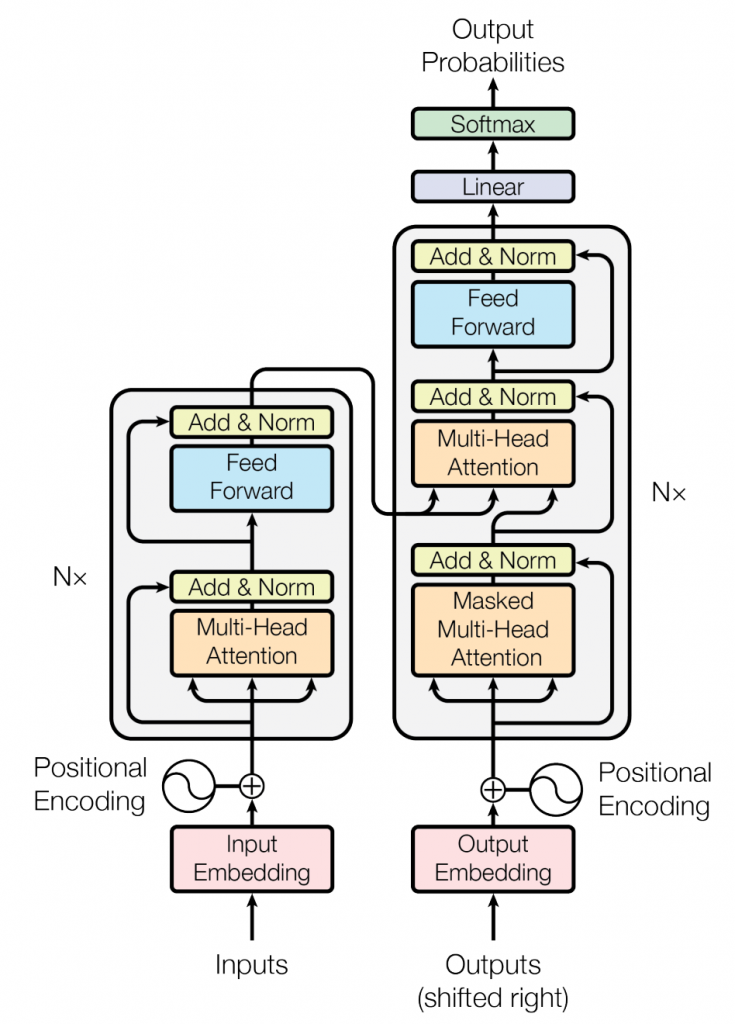
This tells me nothing about how this architecture works at a mechanical level. I would not know where to start if I wanted to build any part of such a thing. I assumed that since I did Andrew Ng’s excellent Deep Learning Specialization five years ago, the state of the art had advanced so far that it was beyond the practical grasp of someone without a PhD in AI. But I wasn’t ready to give up so I did some Googling. I discovered that Adrej Karpathy has a series of YouTube videos called Neural Networks: Zero to Hero where he takes us from basic neural nets to building a version of GPT2— all with actual code!
My Hero
Andrej was an early hero of mine when learning AI. He gave me my first intuitive understanding of how to build reinforcement learning architectures—via his Deep Reinforcement Learning: Pong from Pixels paper—at a time when all I had built were standard classifiers.
The series is amazing. I’m going through it video by video and I’m through the fourth. Most of what he has covered so far is a rehash of what I learned in the Coursera Deep Learning Specialization. The two approaches (both excellent) make for an interesting compare-and-contrast. Both Ng and Karpathy are gifted teachers with a deep grasp of the material they are teaching. What makes them effective teachers, though, is they both know that sharing math or code with students who memorize the math and the code does not add up to understanding. They both recognize how important it is to impart an intuitive understanding of the material. In fact, I believe—and I suspect Ng and Karpathy would probably agree—that no matter how many facts, theorems, and formulas you may know, until you have an intuition for a thing, you don’t really understand it. Both spend a large percentage of their lecture time going over variations and details that are designed to help students build their intuition about the material they are covering.
Most satisfying is that they both get right down to the actual mechanics of how these networks work at the level of the math of the individual neuron. Ng describes, at length, the fundamental concepts that enable machine learning and AI using his virtual whiteboard, drawing clear diagrams of the networks and how they function along with hand-written math to go along with the visuals.
By contrast, Karpathy spends all of his time in Jupyter notebooks explaining the workings of neural nets with actual Python code. He writes code and shows how it behaves in one circumstance, then in another, and yet another. All in support of developing intuition about its behavior.
As excellent as Karpathy’s all-code approach is, I’m glad that I had Ng’s fundamentals under my belt from years ago. Without that, I suspect it would be a lot harder to follow what Karpathy is walking me through now. Interestingly, in Karpathy’s third video, he explained the mechanics of embeddings, one of the foundations of most natural language AI, including Transformers—the fundamental architecture of GPT. And he does it at the level of individual neurons, with code. In this case, he has bested Ng, who really only glossed over this subject at a high level in his course.
This is very exciting.