AI Checkers 2.0
I started actually doing AI again. As I was watching all the Karpathy videos, I found myself wanting to stop watching videos and get back to building. I could have gone out and built Karpathy’s nano-gpt model, but he already built that. What I wanted to do was get back to my AI checkers project. So that’s what I did. Over the past week or so, I made a lot of progress. I am going to capture as many of the details here as I can so as not to lose it to the memory hole.
When I last worked on this, I had put together parallel gameplay and converted my model to TensorFlow. But no matter what I did, the model would explode before getting to 100,000 games. I speculated at the time that it was because I needed normalization layers, which I had learned about but had never implemented. Given that all I was building was a model to make legal moves (which is not the main point and also unnecessary), I had lost steam.
But now, after having seen Karpathy build model after model in PyTorch, I felt as if I understood PyTorch reasonably well. It looked a lot more straightforward than Tensorflow ever did back in 2019. I even saw how easy it was to insert a normalization layer. I decided that if I was going to make any kind of progress with my model, I should convert it to PyTorch. I wasn’t sure how tedious and cumbersome it would be, but I would do it. I accomplished a lot, I learned a lot, and I made some plans.
Accomplishments
Understanding what I built five years ago
It was a lot of work to do the PyTorch conversion. It took about a week. Most of the work, though, was not actually writing PyTorch code. It was reviewing all my old code to unearth how it all works. That code was inelegant and mostly still is. The Tensorflow code in particular is a monstrosity. But now I remember how I built it. I also cleaned up some of it since there was a lot of unused code that had accumulated due to abandoned experiments. This puts me in a better position to move forward.
Accomplishment – Torch Conversion
The model is now built entirely in PyTorch. There is a lot of administrative code in both models, but the actual model code–the layers, the forward pass code, the backward pass and optimization–is much simpler and easy to understand.
Accomplishment – A Stable Model
My model no longer blows up before 100,000 games. I’m not 100% sure why, since I made a lot of changes. I will discuss this more in the section about what I learned. Regardless, I can now train my model seemingly infinitely without the sudden explosion in model parameters and accompanying cratering of model prediction accuracy. In my old setup, with less than 100,000 games and a percentage of illegal moves around 82%, there would be a sudden, catastrophic failure. Note: the image below is a graph of a training run from saved, which already had about 70,000 games:
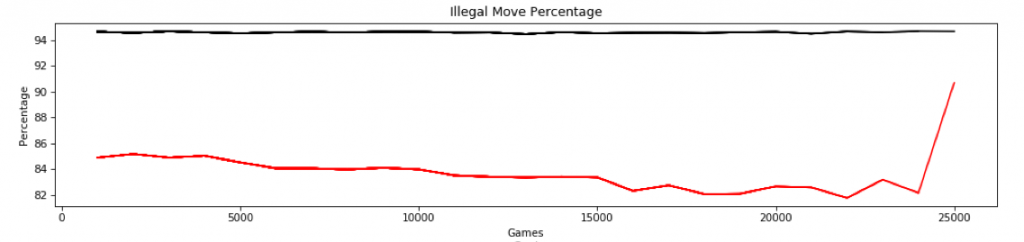
The new model sails through that barrier, both in number of games and percentage of illegal moves. I stopped running it well beyond 500,000 games at which point it was achieving around 30% illegal moves:
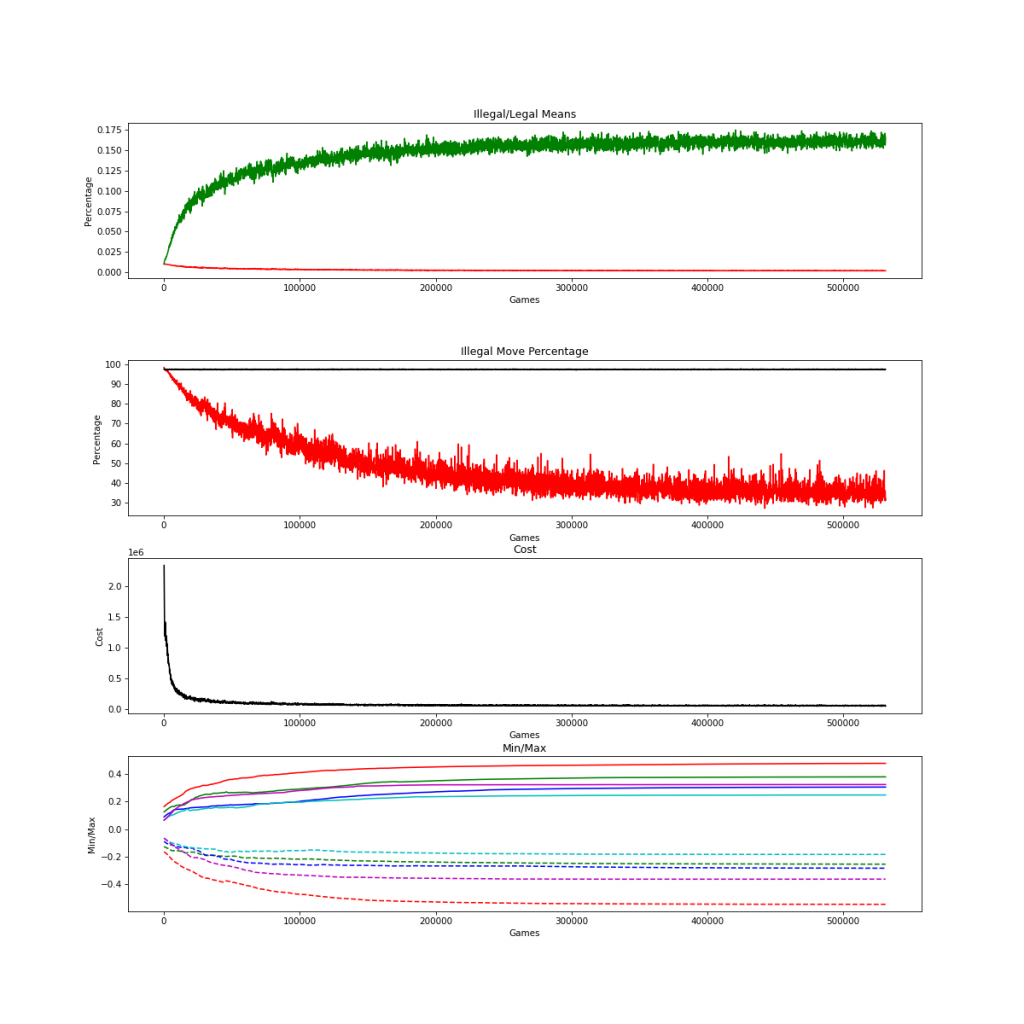
Accomplishment – Optimized Code
In my old model, as the games stacked up, the graphing of metrics would bog down. I found out how to eliminate that issue. Also, when I first implemented the model in Torch, there were a few chunks of code that were accumulating hooks into the network that were not getting purged after each training batch. This was progressively slowing down the code as the games would pile up. I managed to fix that as well. The model runs smoking fast now.
Accomplishment – Layer Normalization
I don’t know if this had anything to do with why the model is now stable, but I added layer normalization. In Torch, it was almost trivially easy.
Things I learned
I learned so much I doubt I’ll even remember it all. But here are some of the big ones.
PyTorch Basics
I don’t know all of it by a long shot. But I know all the basics. I know how to construct a model. I know how to do forward and backward pass. I learned how to extract weights and other parameters from my model to monitor those things as the model was trained. Through a good deal of trial and error, I learned how to write code that is optimized for performance.
Better Matplotlib techniques
I learned how to update performance graphs interactively without having to send the entire data set to the graphs with every update.
The Right Loss Function
It turns out that I was probably using a sub-optimal loss function all this time. I should have been using Policy Gradient Loss with Rewards.
Back when I was making the original model, I deliberately used MSE rather than cross entropy. I had good reasons for making that pick, and I suspect cross entropy is still the wrong answer. However, I have reason to believe that much of the instability my model was exhibiting was due to the loss function I chose. Since converting to PyTorch, I have not seen the catastrophic explosion of weights that I saw when I was using Tensorflow. But with the old loss function I did see at least one instance of the model suddenly catastrophically forgetting what it had learned. In that instance, it recovered fairly quickly within a hundred or so games. But I suspect that behavior is probably closely associated with the explosions I witnessed in Tensorflow. Since switching to Policy Reward Loss, the model has been rock-stable.
The Value of Modifying the Learning Rate During Training
While I was aware that there were benefits to lowering the learning rate as training progressed, it wasn’t until I saw Andrej Karphathy actually do this that it sunk in what a significant impact it could have. While researching how to use PyTorch, I stumbled across learning rate schedulers and decided to give it a try. I found that by selecting the correct algorithm and parameters to adjust learning rate, I could get the model to levels of performance I had not come close to in prior iterations.
That I could learn a lot of what I need from ChatGPT
ChatGPT taught me so much. Five years ago when I was doing this, whenever I would have some question about how to do something in Python, I would go to Stack Overflow. Now I just ask ChatGPT what I need to know and ChatGPT gives me a (usually correct) plain English explanation complete with commented code. It can even hold forth on Pytorch: how it works, how to optimize it, and the possible causes of bugs and performance issues. Most recently, as I prepare for the next phase of what I’m doing, ChatGPT is giving me some of the theory behind how to use Monte Carlo Tree Search, a policy network and a value network in my reinforcement learning model. It feels like a self-directed course on reinforcement learning.
ChatGPT is a goldmine.
Plans
I’ve begun thinking about what to do next.
I’ve learned enough about how to build a model to win games so to get to work on that. However, there are things I need to do with the existing model and training objective (legal moves) still in place. I know that I am going to need to have a setup that enables a model to play against another instance of itself in a competitive scenario. The existing setup nominally allows for that. But I have never actually tested it on two actual models. Only on a model and a placeholder model that does nothing but generate random moves regardless of game state. I need to verify that the current setup behaves correctly when there are actual models on both sides of the board. I need to do this with a model whose behavior I understand so that I can be confident that everything is behaving correctly. I understand how the current model behaves since I’ve been working with it extensively. I will leave it in place and change the gameplay and training frameworks around it. Once I know that I can use two versions of the same model against one another, I will then move on to making a better model to win games.
Also in support of that, I probably need to be able to graph different metrics, and metrics on two models rather than just one.
After I get the setup sorted, I need a better model. I will probably hang on to the fully connected model that I have, but I know that a convolutional model is what I really need. I’ve revisitd conv nets again, and with the benefit of what I’ve learned since, that original material about conv nets now makes a lot more sense. So I will start with a conv net. I may or may not use a residual pathway. That depends on what I can learn about those. I get how they’re used in transformers, but that’s the only application where I’ve seen how to use it correctly. Using that architecture correctly in a convolutional network will take some research.
Interestingly enough, thanks to ChatGPT, I think I have managed to grok at least the basics of how AlphaGo Zero implements and trains policy and value networks in the context of game play and MCTS simulations. With a little more research, I think I may be able to do a scaled down version of what AlphaGo Zero implements. That would be amazing.