Mastering Attention
I’ve been going through Andrej Karpathy’s Neural Nets: Zero to Hero playlist. I’ve spent the last few days on one of the later ones: Let’s build GPT: from scratch, in code, spelled out. As an aside, I should note that throughout these videos, it has been slightly depressing to note how straightforward and elegant his code is. I’ve also been looking through the code for my AI-Checkers project from years ago. Comparatively speaking, it is a monstrosity.
But that’s not what this post is about. This post is about the attention mechanism in the transformer architecture. This whole series has been amazing, and up until now, had taught me the mechanics of two main components of NLP in general that I had not gotten from any of my other courses: embeddings and tokenization. As I mentioned in my last post, Karpathy is gifted in his ability to explain complex subject matter at its most fundamental. He doesn’t just explain it, but takes pains to impart intuition about AI to his students. He did this admirably with everything to this point, including embeddings and tokenization.
However, with his GPT video, he tackles the attention mechanism, which is significantly more complex than either embeddings or tokenization. And unfortunately, he doesn’t go to nearly the lengths he did in prior videos to deliver that intuition. That intuition is what has helped me feel I’ve understood prior concepts. Since I’m doing this to actually understand this stuff, I decided I would need to figure things out myself. So I spent a couple of days diagramming things out so that I could trace all the components of the attention mechanism.
First I was sketching things out using the same dimensions as his example. The examples he uses has a batch size (B) of 4, a time sequence length (T) of 8 tokens, and 16 embedding (and head) channels (C). I did some diagrams with those dimensions to first just see how things laid out, getting a high-level visual sense for the architecture and the operations.
But there were certain components of how an architecture like this behaves that would involve tracing parts of the math through some of the different components. I had to simplify a lot to do this in a manageable way with just freehand drawing. I had to strip things down. First, I got rid of batch altogether since it’s just taking the fundamental operations and doing them in parallel 4 times. Then I used T=2, and C=3.
The diagrams below are what I created.
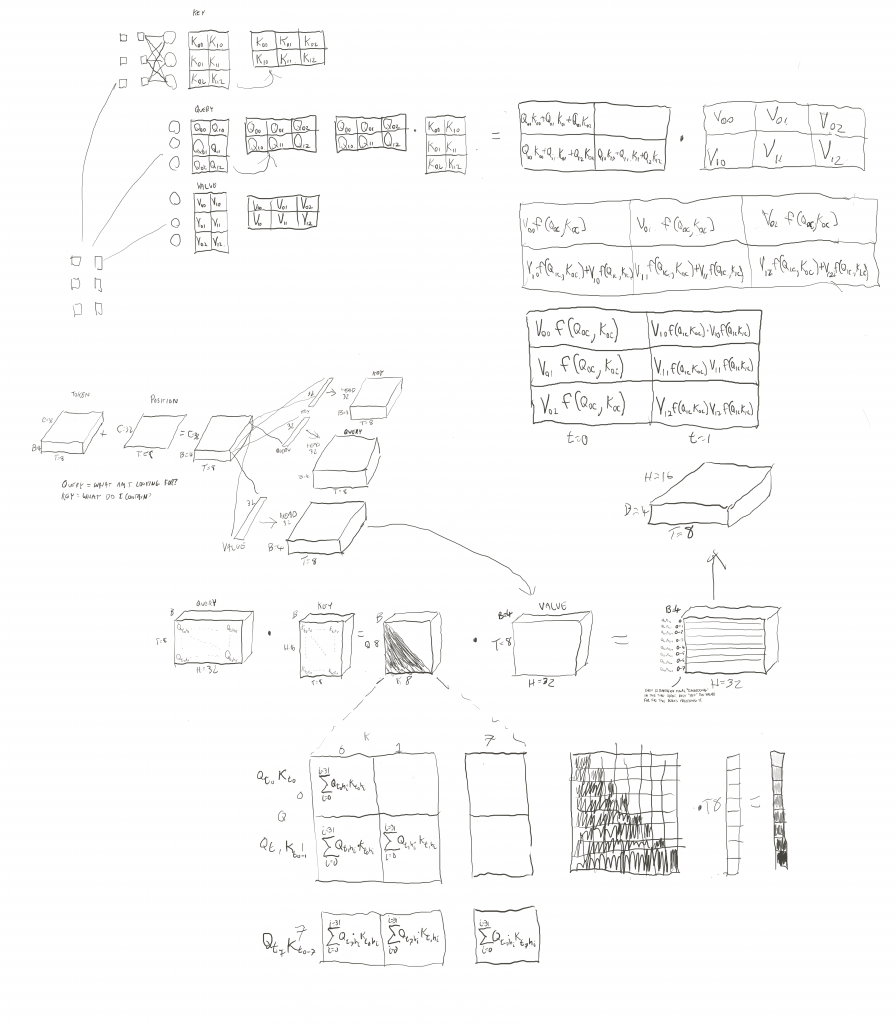
I may annotate this later, but it shows what I need to remember for now.